Content processing workflow Leave feedback
GroupDocs.Rewriter Cloud can paraphrase, summarize, simplify and otherwise process texts and and documents in a number of formats with just 2 REST API calls or a few lines of code in any programming language supported by SDK. Read Hello, world! article for a hands-on example.
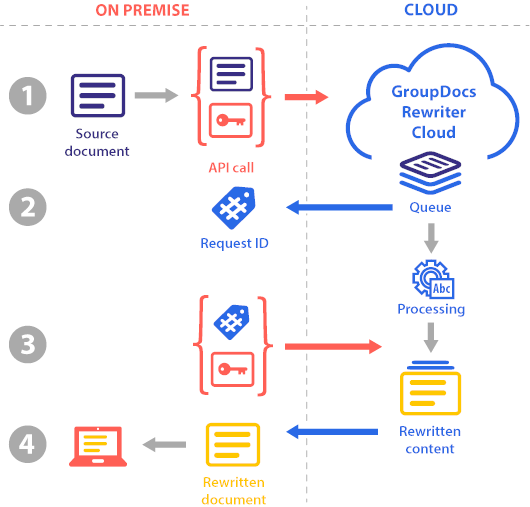
In the request body, provide JSON with a plain text or a Base64 encoded file along with mandatory and optional processing parameters.
To authorize the request to use GroupDocs.Rewriter Cloud, pass the access token in Authorization header of the request (Bearer Token).
NoteIf you are using GroupDocs.Rewriter Cloud SDK, you do not have to worry about content encoding, getting an access token, setting request headers, and other technical details. The SDK will perform all routine operations: from establishing a connection with the GroupDocs.Rewriter Cloud API to receiving and parsing the response.
Your content processing request is queued and you will receive a unique identifier that can be used to retrieve results.
For more information on what happens in the cloud, read Behind the scenes section.
Just call the GroupDocs.Rewriter Cloud API with the ID of the request received on the previous step to retrieve the processed content. The processing may take a second or two, depending on the file size and complexity and the current GroupDocs.Rewriter load. For more information on what happens in the cloud, read Behind the scenes section.
To authorize your request, pass the access token in Authorization header.
NoteIf you are using GroupDocs.Rewriter Cloud SDK, it will handle all authorization routines.
If the processing is successful, you will receive the results in JSON format along with processing statistics. Processed files are returned as URLs which can be downloaded, displayed on the screen, or written to a database. Processed text is returned as an array of strings.
NoteGroupDocs.Rewriter Cloud SDK takes care of all the routine operations so you can get content directly with no extra effort.
Natural language processing is a resource-intensive process that involves sophisticated neural networks and complex calculations. Even with high-performance servers, this can take some time, especially when processing large amounts of content and reading large files.
To balance resources under high load and ensure reliable and secure operation, we have introduced queued processing. Instead of being immediately processed, the source text or file is placed in a queue under a unique identifier. The queue is constantly monitored and processed in the background using advanced load balancing techniques.
Once the processing is finished, the result is saved to internal storage, from where it can be retrieved using the unique ID within 24 hours after a content processing request has been made.
Was this page helpful?
Any additional feedback you'd like to share with us?
Please tell us how we can improve this page.
Thank you for your feedback!
We value your opinion. Your feedback will help us improve our documentation.