Report Generation Concepts Leave feedback
On this page
GroupDocs.Assembly Cloud is a powerful web-based Document Automation and Report Generation solution, designed to generate data-bound documents through templates dynamically.
The main Report Generation concept, presented on the image below, is simple and consistent:
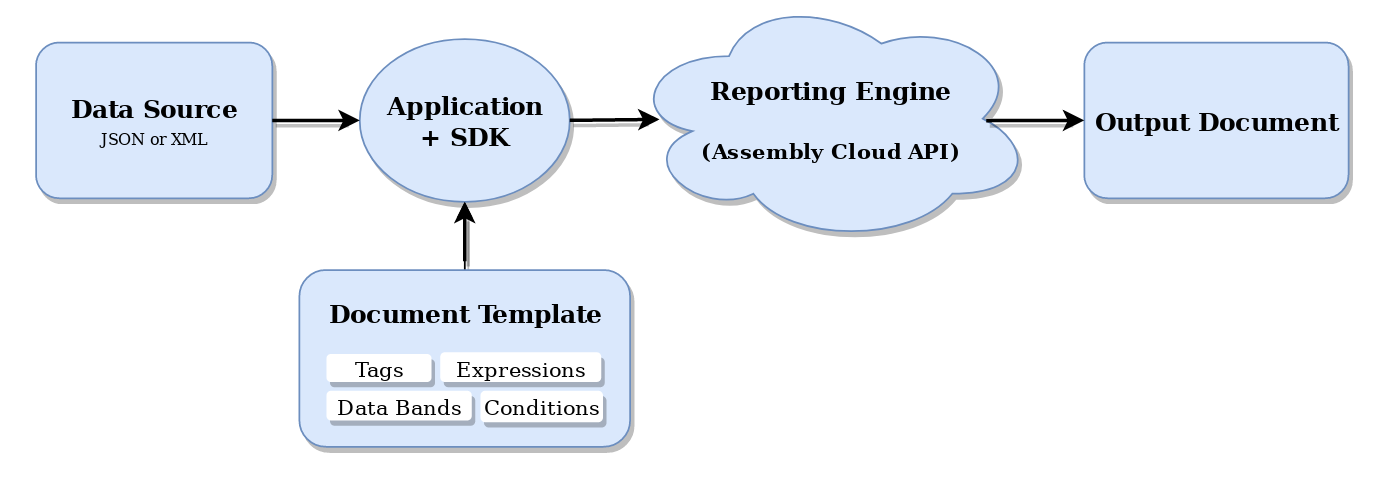
A document template is just a normal document, created with Microsoft Office, OpenOffice or any other compatible office suite (LibreOffice, WPS Office, Polaris Office, Open365, SoftMaker FreeOffice, etc.), that contains special tags for the dynamic content. You are supposed to use that template to assemble documents on this model repeatedly and consistently.
Have a note, that supported template types are not limited to word-processing document templates only, but also include spreadsheet templates, presentation templates, HTML document templates, email document templates, plain-text templates and others.
A Data Source lets you define which data set will be used to bind with a document template and subsequently evaluated in the output.
You can use both JSON and XML files for this purpose. Both formats are hierarchical, self-describing and human-readable. However, JSON may have slight built-in advantages, because it is more compact and thus it is quicker to read and write.
You can use the following simple data types in your JSON and XML files:
| Data Type | Description | XML Example | JSON Example |
|---|---|---|---|
| Int32 | A 32-bit signed integer |
|
|
| Int64 | A 64-bit signed integer |
|
|
| Double | A double-precision floating-point number |
|
|
| Boolean | A boolean value (True or False) |
|
|
| DateTime | An instant in time |
|
|
| String | A sequence of Unicode characters |
|
|
Tags and Expressions are the fundamental elements of the report generation technique, that are located in the document template and intended for the purposes of dynamic content management. At its simplest, a tag defines a command for the Reporting Engine, and the expression, which is an integral part of the tag, defines command’s parameters.
In terms of the Reporting Engine, it does not matter what type of document templates you are working with — regardless of the document template type, tags and expression syntax remains the same anywhere. However, you need to use character escaping when working with HTML templates.
A tag is surrounded with a pair of “<<”, “>>” character sequences and consists of the following elements: name, expression, switches and comment:
<<tagName [expression] -switch1 -switch2 ... //comment>>
Some tags require a corresponding closing tag. A closing tag must match the name of the opening tag with the “/” character preceding its name:
<</tagName>>
Depending on the functional role, the following types of tags can be distinguished:
| Tag Type | Functional Role | Tags | Tags Description |
|---|---|---|---|
| Control Tags | Provides flow and conditional processing control | foreach, next | Provides flow control for traversing elements of a certain type in a sequence |
if, else, elseif | Provides conditional processing control | ||
| Content Tags | Used to generate and insert different content elements into the output dynamically | backColor | Defines a background-color for a text |
barcode | Inserts a barcode image | ||
check | Sets a checkbox value | ||
link | Inserts a hyperlink | ||
restartNum | Restarts a numbering inside a list | ||
var | Declares a variable | ||
| Chart Tags | Used to populate charts with data | pointColor | Defines a color for a chart series |
removeif | Removes a chart series, depending on the condition | ||
seriesColor | Defines a color of a chart series | ||
size | Defines a bubble size for a bubble chart | ||
x, y | Specifies a data mapping for chart coordinates |
Expressions are the most interesting part of a tag syntax. They are composed of operands, usually presented in the form of Data Field references, and Operators, defined according to the “C# Language Specification 5.0”.
A Data Band is a template for sequential data processing. During the document generation process, the Reporting Engine connects each data band to a data source using Data Field references and processes it as many times as there are records in the data source. As a result, the data band body is replicated and appended to the output document.
A data band is made up of two parts:
- A pair of opening and closing
foreachloop tags, that represent the scope of a control flow statement for traversing elements in a sequence. Depending upon the developer’s objectives theforeachtag syntax may vary. - A Data Band Body, defined between the
foreachpair of tags, which represents a template for a single element of a sequence. A data band body may contain nested data bands.
The complete syntax of a data band is provided below:
<<foreach [varType varName in sequence]>>data_band_body<</foreach>>
An iteration variable, defined by name and type, is intended to reference an element of a sequence inside a data band body.
Variable’s name and type are optional parameters, that can be specified or omitted depending on the aspects described in the following table:
| Parameter | Use Aspects |
|---|---|
| Variable Type |
|
| Variable Name |
|
When a data band is related to a list, it is called a Common Data Band.
When a data band is related to a table, that is to a single or multiple rows of a table, it is called a Table-Row Data Band.
Depending on the objectives, this type of data band may occupy a different number of table rows. In the simplest cases, it occupies a single row, but in more complicated scenarios, that imply generation of hierarchical tabular data structures, using multirow data bands may be required.
To reference a field inside a data source you must provide a string representation of it.
A field reference syntax is straightforward:
<<[field_reference]>>
To make this baseline technique clear, let’s have a look at the sample data sources in XML and JSON and the corresponding data band.
The following XML and JSON data sources represent a list of persons, described by their names and ages.
| XML Data | JSON Data |
|---|---|
| |
The corresponding table-row data band is shown below. As you can see, it is referencing the Name and Age fields inside the ds data source, and intended to output the sequence of Person elements to a tabular format in three columns:
| Number | Name | Age |
|---|---|---|
|
|
|
| Count |
| |
When the report generation process is complete, you’ll see the following output:
| Number | Name | Age |
|---|---|---|
| 1 | John Doe | 30 |
| 2 | Jane Doe | 27 |
| 3 | John Smith | 51 |
| Count | 3 | |
You can also use the Contextual Field Access technique, which enables you to access fields of a data source depending on the processing context. An object, to which the Contextual Field Access can be applied, is determined by the following rules:
- Inside a data band body, the object is resolved to the iteration variable.
- Outside a data band body, the object is resolved to a passed data source.
The main syntax differences between the standard and the contextual types of field access are submitted in the following table:
| Type of Field Access | Iteration Loop Syntax | Field Access Syntax |
|---|---|---|
| Standard |
|
|
| Contextual |
|
|
The complete table-row data band example, that demonstates the Contextual Field Access technique, is provided below:
| Number | Name | Age |
|---|---|---|
|
|
|
| Count |
| |
While building a report, paragraph breaks derive attributes from their template prototypes. In particular, this fact enables you to build numbered or bulleted lists in reports dynamically.
The following table illustrates some common use-cases with a “¶” symbol, that represents a non-printing control character of a paragraph break.
Given an enumeration of strings ["item1", "item2", "item3"] and a common data band in the left column of the following table, you will get the output, shown in the right column:
| Data Band | Output |
|---|---|
| |
| |
| |
| |
You can instruct the Reporting Engine to force movement to the next iteration within a data band using the next tag. This feature is useful in scenarios when you need to output data of a fixed number of elements in a single row.
In the following example, given an enumeration of Person data elements, you can output their names in a row using the following table-row data band:
| Name A | Name B | Name C |
|---|---|---|
|
|
|
The result would be as follows: